Controlling & Finančná analýza | MS Excel
Rozdeľovanie textu v MS Excel
Nepohodlné rozdeľovanie dát z exportovaných súborov je možné urýchliť jednoduchými textovými funkciami
28.05.2014 | Zdroj: CFO.sk
CFO.sk
V prípade exportu dát z rôznych informačných systémov do Excelu sa niekedy stáva, že exportované údaje zostanú zoskupené v jednej excelovej bunke. Napríklad pri exporte mien zamestnancov sa meno aj priezvisko vyexportuje do jednej bunky a zostane oddelené medzerou alebo čiarkou.
Ak je potrebné rozdeliť väčšie množstvo textových dát, Excel ponúka textové funkcie, ktoré prácu urýchlia.
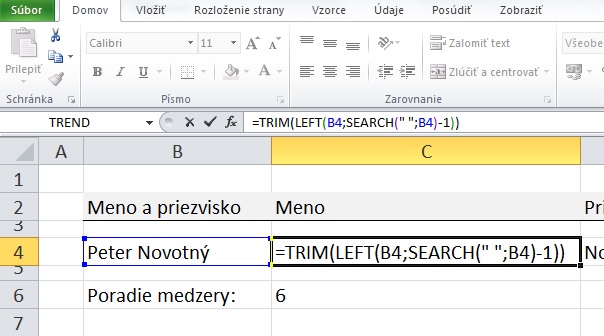
V príklade nižšie je popísané rozdelenie mena a priezviska do dvoch samostatných buniek:
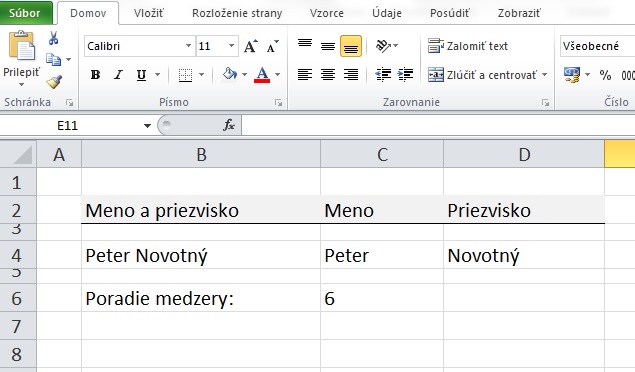
V prvom kroku je potrebné identifikovať pozíciu znaku, ktorý rozdeľuje text, v tomto prípade sa jedná o medzeru. Na to je možné použiť funkciu SEARCH, ktorá vráti pozíciu hľadaného znaku v textovom reťazci. V našom prípade bude vyzerať nasledovne: SEARCH(" ";B4)
Funkcia SEARCH má nasledovné argumenty:
SEARCH(nájsť_text; v_texte; [pozícia_začiatku])
pričom v prvom argumente zadávame do obojstranných úvodzoviek znak, ktorý hľadáme, v druhom argumente odkazujeme na text, v ktorom hľadáme znak (v našom prípade bunka B4). Tretí argument je voliteľný a predstavuje číselné poradie znaku, od ktorého má funkcia SEARCH začať hľadať. V našom prípade chceme začať hľadať poradie medzery od začiatku textového reťazca, a argument preto nemusíme zadávať.
V príklade vyššie je medzera šiestym znakom v poradí a funkcia SEARCH(" ";B4) vráti hodnotu 6.
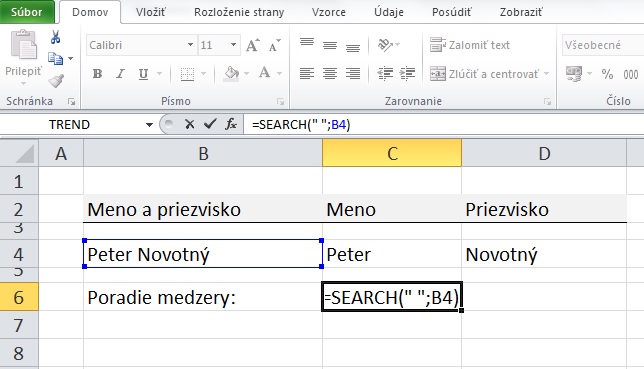
Keď sme určili pozíciu medzery, potrebujeme z bunky B4 vytiahnuť textový reťazec, ktorý sa nachádza naľavo (krstné meno) a napravo od medzery (priezvisko). Na to využijeme funkcie LEFT a RIGHT.
Krstné meno vytiahneme z bunky funkciou LEFT nasledovne: LEFT(B4;SEARCH(" ";B4)-1)
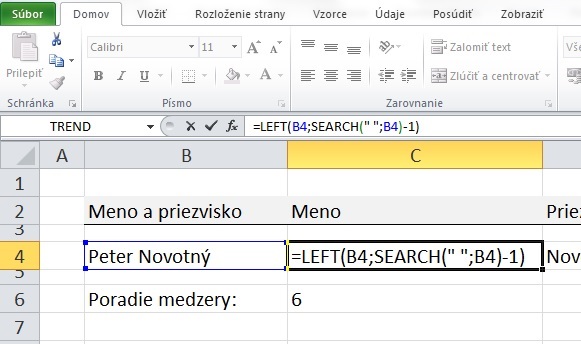
Funkcia LEFT vráti prvých x znakov z textového reťazca začínajúc zľava a končiac na znaku s poradím x. Má nasledovné argumenty:
LEFT(text: [počet_znakov])
pričom v prvom argumente odkazujeme na text, z ktorého chceme vytiahnuť prvých x znakov (v našom prípade z bunky B4), druhý argument udáva počet znakov x, ktoré chceme vytiahnuť. Na výpočet druhého argumentu použijeme výsledok funkcie SEARCH vyššie. Ak nechceme za vlastným menom medzeru, potrebujeme iba prvých 5 znakov, preto od funkcie SEARCH, ktorá vrátila hodnotu 6, odpočítame 1.
Druhý argument funkcie LEFT (počet znakov) je voliteľný, ak ho vynecháme, funkcia vráti prvý znak textového reťazca.
Podobným spôsobom funguje funkcia RIGHT, ktorá vyhľadá posledných x znakov v textovom reťazci. Má rovnaké argumenty, ako funkcia LEFT. V našom prípade má celý textový reťazec 13 znakov, medzera je na 6. pozícii a potrebujeme teda z bunky B4 vytiahnuť posledných 13-6=7 znakov.
Aby sme zistili, koľko znakov z pravej strany chceme vytiahnuť (druhý argument funkcie RIGHT), využijeme funkciu LEN, ktorá vracia celkový počet znakov textového reťazca v bunke: LEN(B4)=13. Funkcia RIGHT potom bude vyzerať nasledovne: RIGHT(B4;LEN(B4)-SEARCH(" ";B4))
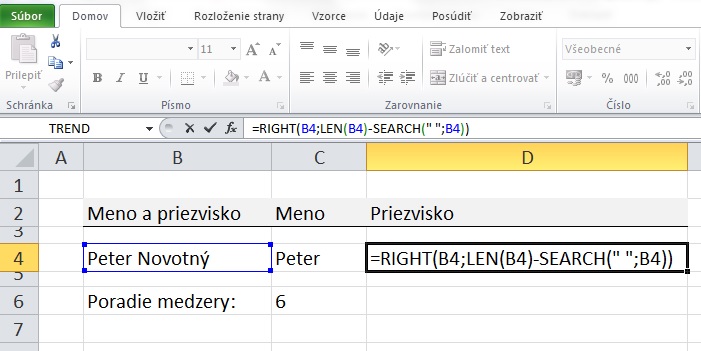
Do druhého argumentu funkcie RIGHT sme vnorili vyššie popísané funkcie LEN a SEARCH, ktoré vrátia výsledok 13-6=7 (t.j. druhým argumentom funkcie RIGHT je číslo 7).
Ak si chceme byť istí, že vrátený text v novej bunke neobsahuje na začiatku ani na konci žiadne medzery, môžeme použiť funkciu TRIM, ktorá odstráni medzery na začiatku a na konci reťazca, ale ponechá medzery oddeľujúce jednotlivé slová.
Zvoľte si bezplatné zasielanie newslettera e-mailom alebo RSS správ a zostaňte informovaní o novom obsahu na CFO.sk.
Dajte nám vedieť Vaše pripomienky a podnety k portálu - napíšte nám na cfo@cfo.sk.